

Our team faced an interesting task at one of the projects and we would like to share it with you.
The task was to analyze and calculate the flow of customers in the office. For similar tasks, there are many solutions, such as using convolutional neural networks (CNN), such as YOLO (You Only Look Once), SSD (Single Shot Detection), R-CNN, etc. But since the input was video fragments of various resolutions and formats, depending on the model of recorders and the settings that were set, it was decided to try the Background Subtraction method. We also wanted to try this algorithm, because before that we had not encountered it and it was interesting what it was capable of.
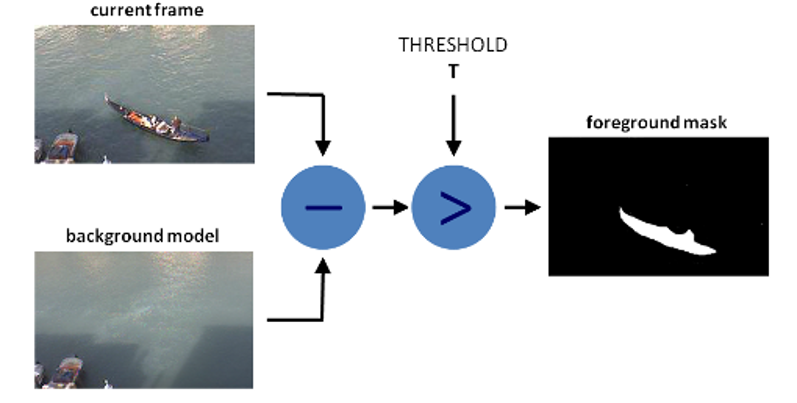
This method is based on the background, as the name implies. The basis is a comparison of the next frame with the previous ones for changes. That is, if the background did not change or not strong changes (foliage swaying, cloud movement, etc.), then this method will not select the area data in the frame and video. There are also a huge number of internal algorithms on which Background subtraction is based, which determine changes in different ways. Some algorithms that are very sensitive to changes, that is, light rain, not strong changes in tree crowns due to wind, all these objects will be visible on the algorithm mask. Other algorithms build masks very roughly, combining many pixels into one object, that is, two people moving side by side will be defined as one person, therefore, it is important to choose the right algorithm for your task and try various settings (number of frames for comparison, border for cutting areas, etc.)


There are also various settings inside the algorithm that can improve quality, and the final mask looks much better for identifying objects.

After additional settings and writing additional code, in order to isolate the variable areas and further count the client flow, it turned out to achieve a good result in terms of counting the number of people, it was also the first experience working with the CV2 python library methods, without using neural networks.
Unfortunately, this method has its drawbacks, this selection of some artifacts, plus it has limited functionality and a narrow scope of use, but as an experience and familiarity with the capabilities of Computer Vision is a great opportunity.
We suggest taking advantage of our experience in using open tools and services to solve computer vision problems.
📖 This case study is part of our complete AI & Machine Learning Development Guide — explore computer vision architectures, deep learning, and real-world AI applications.




About The Author: Yotec Team
More posts by Yotec Team