
In this article, I will share my experience of implementing Agile on a Data Science project from scratch. I will tell you step by step what the team and I tried to use, what it led to, what mistakes we made and how we ended up with a stable, simple and understandable development process.
Project context and some introduction
The project with which I had to work is connected with the definition of objects by surveillance cameras at physical objects (restaurants). Our main task was to create a system for identifying objects and displaying the necessary information on a dashboard, and we also deployed the system at objects (more than 1500) and supported users.
Our team consisted of Data Science and Computer Vision specialists, there were several QAs, one Frontend Developer and one Backend Developer. I acted as Project Manager.
When I first started working on the project, there was no documentation, plan, reporting, etc. Everything was done in words, something was tracked a little in Trello, it was still chaos.
In this article, I will explain more about the development process. The project also had a very complex deployment and user support process. I will not touch on these processes in this article.
Stage 1. Start implementing Agile
At the very beginning, my main goal was to understand what generally needs to be done, by what date, who is doing what and what is there now.
On the Internet, I came across a whole bunch of different articles on how to build processes in DS, but everyone had different opinions: someone advised Kanban, someone Scrum, someone described their methods, but I did not find anything in common. there was nothing that could be applied to any project of this kind. However, the most valuable thing was the familiarity with the CRISP-DM concept.
CRISP-DM . The concept is easily googled, but the main idea is clear from the graphical diagram:
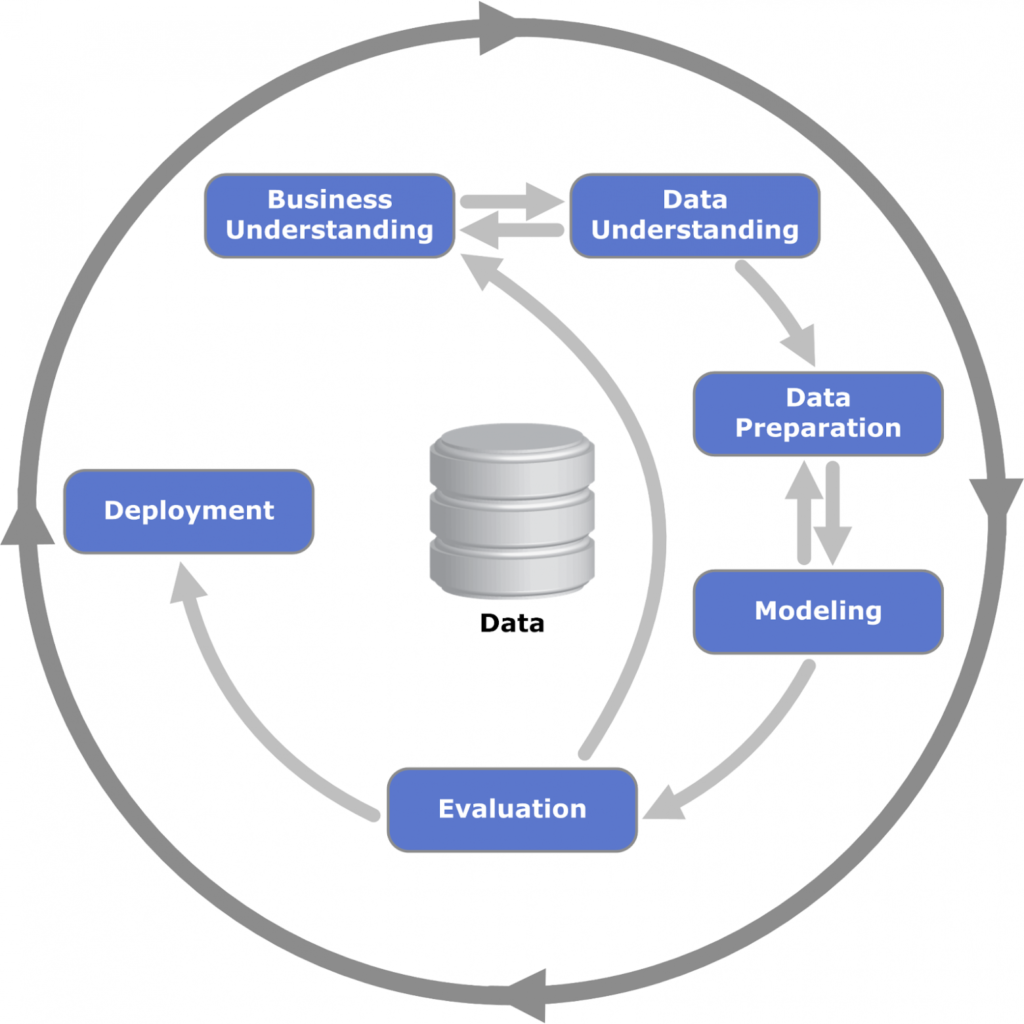
As you can see, due to the possibility of returning to the previous stages, and also due to the fact that the final result may still not be good enough, we cannot give the customer the exact terms, which makes any planning extremely difficult.
Here are the tasks I set myself at the very first stage:
- Definition of all requirements for the project
- Determining the current result
- Setting specific tasks for the team
- Assessment of tasks and formation of a plan
- Choosing a development process
Here’s what exactly was done in the first stage:
- We started using Jira. I had to train the team, since no one had worked with this system before
- We created a Kanban board with standard steps like To Do, In Progress, Test, Done
- I described all the requirements to the team and together with the team we set the first tasks, formed the product backlog. I had to clarify everything with the team, since it was completely unclear what had already been implemented and how this or that requirement was specifically implemented with the DS and CV tools
- Evaluated tasks in days with the team and agreed on deadlines with stakeholders
- We made joint chats, etc., so that communication was finally centralized.
- We started holding general meetings every Monday and synchronized.
- We decided to try using Scrum, after which I went to set up the board and prepare training for the team.
What are the main problems we faced:
- Setting a task in the form of a User Story or just a description of a business requirement is poorly understood by the team, causes incorrect expectations from the customer, and it was difficult to take into account some related work within the task, such as collecting and marking up data, etc.
- The team worked very poorly with Jira. I always had to move tasks and update the board forcibly …
- The task cycle was very long due to the very general task and could take up to 3 months
- After a month of working on the task, the team could understand that they would not be in time on time, since the model was poorly trained or the data was wrong, etc. and you always had to move the deadlines a lot, since one more iteration could take up to 2 months
- The deployment of the project to the objects was extremely chaotic, it was done on demand and problems constantly arose
We analyzed these problems and decided to try Scrum (oddly enough, it sounded logical then)
Stage 2. Scrum
Before starting development using Scrum, I carefully rebuilt the general project backlog, described it in the format of ordinary Tasks and User story, and prioritized it.
At the very start, our Scrum board had the same columns To Do, In Progress, Test, Done
The team and I conducted the first planning, during which we discussed the backlog and once again discussed the principle of working with Scrum. In the course of planning, we got the following:
- We discussed the CI / CD process and decided to add a UAT environment.
- Added the corresponding status on the board – UAT
- Evaluated tasks in story points
- Set tasks for the sprint
- We talked about the rules of work and responsibility
After completing several sprints, it turned out that each sprint closes a completely different amount of SP: 26, 62, 28 (for example)
After another retrospective, we decided to start breaking down the current tasks into much smaller ones, since many tasks took more than 2 weeks to complete.
After that, we spent another sprint 3. We tried to formulate these tasks differently, break them down into related tasks, and so on.
As a result, we managed to achieve some kind of stability, but the completed tasks did not carry any ultimate value and as a result of the sprint we did not receive a release, we just received a set of completed tasks.
We decided to make another attempt and just increase the sprint duration to 1 month, but the situation did not change much + urgent tasks began to arrive that could not wait 1 month and we had to break our plan.
And we got together for a full analysis of the situation in anticipation of finding some kind of radical solution that will help us.
We saw that it is impossible for us, in principle, to close tasks with sprints, since work on, for example, a new model to determine the fact of payment by a client can take up to 3 months, and then we still have to return to this task, retrain the model, etc. … It’s impossible to fit this into a sprint.
As a result, we decided to move on to Kanban and try this practice.
3. Kanban
So Kanban! We took LeanDS as the basis for building the development process.
You can find a link to the book on the Internet.
I made a new board and indicated the following steps there:
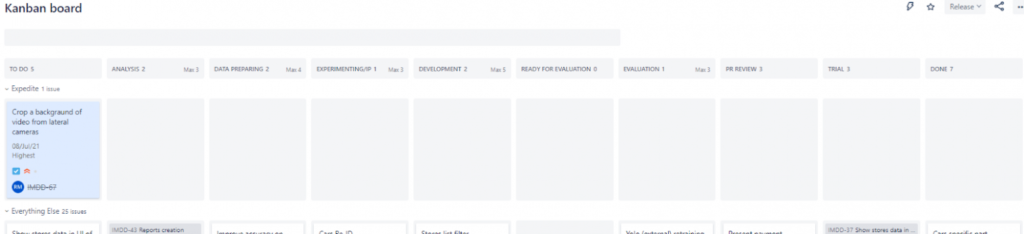
To Do, Analysis, Data Preparing, Experimenting, Development, Ready for Evaluation, Evaluation, PR review, Trial, Done
I set limits (WIS) at each stage, which I indicated in accordance with the number of team members involved in a given stage
I also revised the backlog and divided the work on the models into hypotheses, other tasks remained in the User stories as before. The backlog has been prioritized once again.
Example Hypothesis:
We believe that we will solve the problem of the appearance of ghost machines on all objects. To do this, we will locate each real car at the current time. We will be right if, in situations that cause the appearance of guest cars now, they will not appear and if the number of requests from restaurants about this problem will decrease by at least 50%
After all the preparations, my team and I carried out Kanban planning and agreed to work in accordance with the rules and ideology of Kanban. We chose the first tasks and started work
The result was colossally different from what it was before and it began to look promising:
- We could take super urgent tasks and get them done right away
- We could immediately see at what stage our tasks are stuck
- We began to understand how to better allocate resources
- Tasks began to move more actively through the funnel, as the team was able to better concentrate on specific tasks and began to help each other more
- We began to release features immediately after the readiness and this suited the customer even more, and it allowed us to simplify the deployment (at least the approval process) and analyze the impact of certain features independently of each other.
Another 2-3 weeks passed, the process stabilized, we began to notice how and where it was possible to expand the narrow necks in the process. We started to apply solutions and gradually accelerate development even more.
For example, we decided to centralize data collection, allocate a separate group for this and harvest some types of data on an ongoing basis, so that there are always fresh datasets for retraining old or training new models.
Thus, we have come to the ideal work format for our team.
I tried to summarize the very essence, without describing unnecessary details and water, and also show why we made certain decisions and what it led to. I hope this article will be useful to you and will help you in your practice.
PS I highly recommend reading the LeanDS book for managers or Data Science engineers, as this will greatly improve at least some aspects of your processes.




About The Author: Yotec Team
More posts by Yotec Team