

The whole world is a model, and LLM is the backend in it
At any stage of AI development, philosophical or so discussions are actively going on. Now, for example, we are arguing about what AGI or world model is. The latter concept first appeared probably several decades ago, but it was brought to a new level by Yann LeCun.
How can we make machines learn as efficiently as humans or animals? How can machines learn representations and plan actions at multiple levels of abstraction? To do this, according to LeCun, a machine needs the same internal model of the world that animals have. When he spoke about his future vision for AI in 2022 , there were more questions than answers. Since then, the concept of a world model has gradually come into circulation, although it is still not entirely clear what is meant (more recently, LeCun gave something like a formal definition of a world model – screenshots below) But nevertheless, something what is called the world model appears.

Modern AI systems often use event-driven architecture — learn how to build microservices with Kafka.
LAW
Authors from the University of California at San Diego and Johns Hopkins University combined the concepts of language ( L anguage), agent ( A gent) and world ( W orld) models into one “law” – LAW (article). They started from the fact that LLM, even having achieved enormous success and become the most advanced example of artificial intelligence, easily makes mistakes in the simplest reasoning and planning.
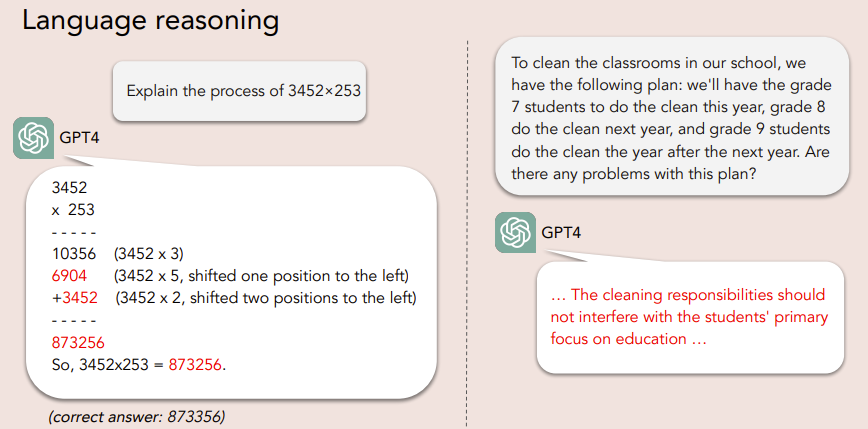
And it doesn’t seem like something that can be solved by increasing the size of the model yet again. This reflects a fundamental limitation: natural language is inherently ambiguous and imprecise, and therefore ineffective as a reasoning tool in many situations. When a person speaks or writes, he omits a gigantic layer of the most important context – from his own psychological state to general common sense. LLM, on the other hand, generates text only formally, without relying on physical, social or mental experience. In other words, a person relies on a certain model of the world, whatever it may be, and forms his ideas. Based on them, a person makes decisions – this is guided by the “agent model”. The authors propose to transfer approximately this concept to artificial intelligence.
Since there are no established definitions in this field yet and everyone uses something different, now we will use the definitions of the authors of the article.
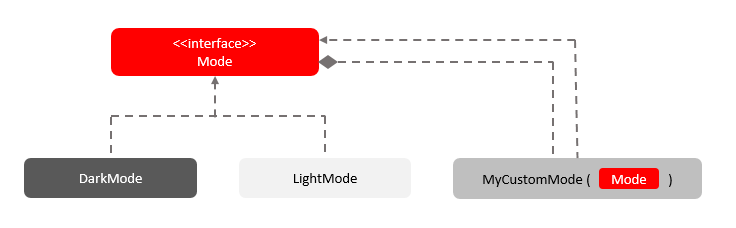
World model – mental representations that an agent uses to understand and predict the external world
Agent-based model – includes a world model and other important components, including the agent’s goals, his beliefs about the current state of the world and other agents.
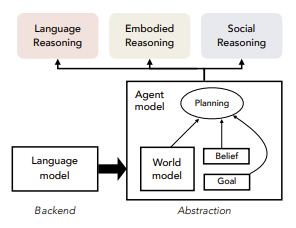
The language model in the LAW concept is the backend part. The reasoning should be built not by the LLM itself (which is not always flawless in this), but by the agent and world models. They, according to the authors, have a greater degree of abstraction and can take into account things that are important in human reasoning: beliefs, expectations of consequences, strategy.
To learn about the physical world, text alone is, of course, not enough. The world model will have to learn from human demonstrations, human interaction, and necessarily from real physical experience. And then a pleasant coincidence occurs, as when two groups of construction workers dig a tunnel from two different entrances and finally meet in the middle. For the rapid development of AI robotics, exactly the same thing is missing – real physical data for training. In 2021, OpenAI, without attracting attention, suspended the robotics team simply because there was no data on which to teach robots (the head of the department, Wojciech Zaremba, spoke about this in a podcast). Google Deepmind did something different and created AutoRT (article , blog), which has collected thousands of real-life examples of robots performing various tasks.
This limitation ties back to the fundamental question of whether AI can truly understand meaning.
AutoRT
AutoRT uses ready-made basic models – a vision model examines the situation and position and describes what it sees, LLM generates tasks, another LLM selects the most suitable ones and sends them to the robot for execution.
The authors launched a fleet of 20 robots (the system can operate on an arbitrary number) for seven months in 4 different buildings on their campus.
While Google employees continued their studies in the background, robots drove around the office and looked for tasks for themselves. A little more about the internals of AutoRT: VLM creates a free-form description of the environment, lists the objects that the robot sees. For example, “I see a pack of chips and a sponge.” The language model offers several tasks, for example, “open the chips,” “wipe the table,” or “put the packet on the table.” These assignments are sent to the court of another LLM, which operates in accordance with the constitution. She decides which of these tasks the robot cannot perform, which ones it can only do with the help of a person, and which ones it can handle on its own. This is necessary so that AutoRT can safely work in a more diverse environment with unknown objects.
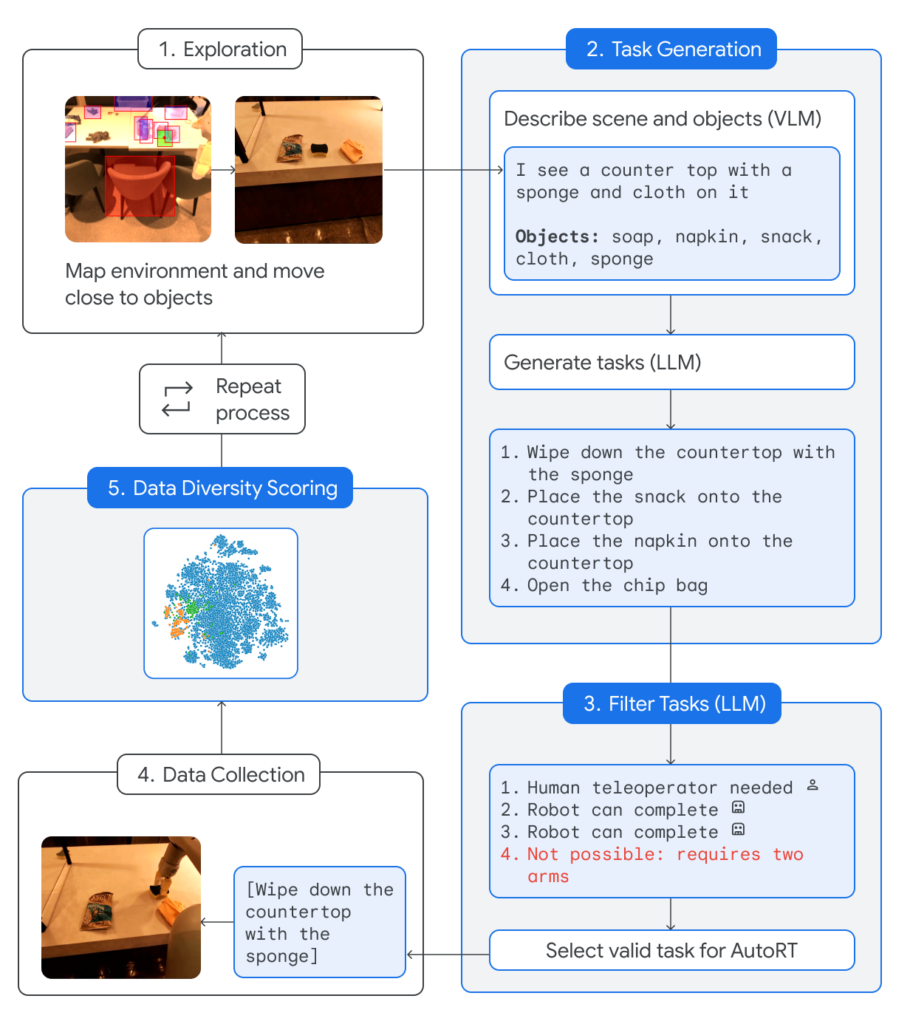
Let us return once again to the very constitution by which suitable tasks are selected. It essentially replaces fine tuning with a set of rules. The rules themselves are divided into three categories. Firstly, the basic rules are approximately the same as in Isaac Asimov’s three laws of robotics:
- A robot cannot harm a person
- The robot must protect itself, unless this contradicts the first point
- A robot must obey human commands unless this violates the first two points.
Secondly, safety rules that prohibit tasks with living beings, sharp objects and electricity. Thirdly, physical limitations – a single hand and a ban on lifting anything heavier than a book.
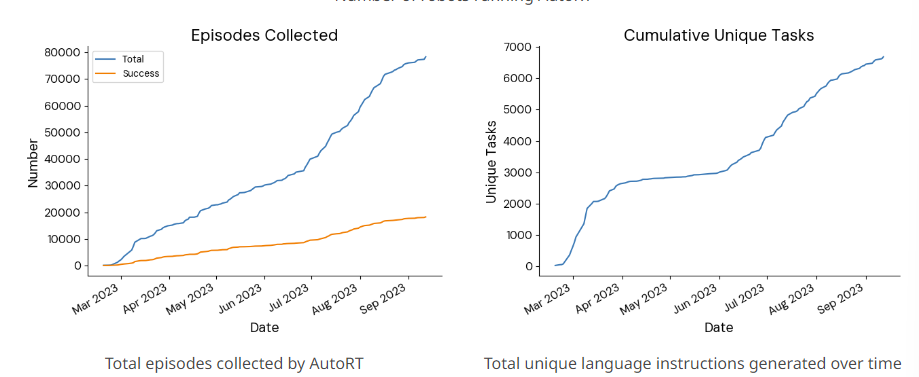
Sometimes employees prevented the robot from completing a task (for example, they put a pack of chips back in the drawer). As a result, in seven months the fleet of robots collected 77,000 unique tasks.
For contrast, here is a short example of a different approach from the MIT team (blog , article). Here the authors do not build a world model and do not wait for synchronized data to train robots. Instead, they trained separately an LLM that divides the task into subtasks, a diffusion model that generates a visual representation of the subtasks, and a module that generates the actual command. The three modules are connected by iterative feedback.
This approach also has a right to exist. In the end, it allows you to achieve results with the tools that you already have. It will now be interesting to see whether training on data received from AutoRT will be better than unsynchronized training of individual modules and whether the concept of a world model will justify itself.
Interested in building world models or agent-based AI systems for your product? Our AI/ML and LLM solutions team can help you explore these cutting-edge concepts.
📖 Want to understand LLMs in a broader context? Read our complete AI & Machine Learning Development Guide — covering LLM strategy, RAG architectures, and enterprise NLP.


About The Author: Yotec Team
More posts by Yotec Team