
Few people are interested to read successful stories, but problems are another matter. Therefore, this post is about problems, misunderstandings and (in places) heroic solutions. Along the way, I will clarify some of the specifics and basic principles of Kafka’s work, so even if you have never worked with her, feel free to read – it will be interesting, and your start with Kafka will probably be easier. I deliberately will not indicate the names of the configuration parameters, you can google all of them.
Bootstrap Servers
We will start from the beginning, namely with the connection to Kafka.
When connecting to Kafka, you need to specify the so-called bootstrap servers (and here are the English terms). Usually, the addresses of all brokers that make up the cluster are indicated. But in fact, it is enough to indicate not all, but only some of the brokers. Why?
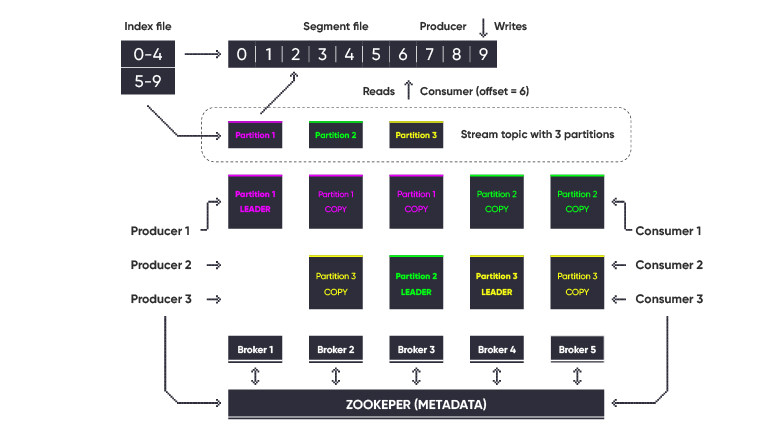
For an answer, let’s take a look at how clients connect to Kafka. When connecting, the client specifies the topic and its partisan (more on partishe will be further on). To start writing to / reading from this partition, you need to connect to its leader, which is one of the cluster brokers. The authors of kafka took pity on us, the developers, and saved us from the need to look for a leader on our own. You can connect to any of the brokers, and he will already reconnect to the leader.
That is, to successfully connect to the cluster, it is enough to know the address of just one broker. Why transfer a list?
And the list allows you to increase the availability of the cluster in cases where some of the brokers are unavailable. The client connects to the brokers from the list in turn until some one answers. So for local development and testing, you can use one address, and for sales, three is quite reliable (two brokers are allowed to be unavailable, and this is an extremely exceptional situation). All brokers can be specified, but impractical.
Retention
Kafka, on the one hand, is as simple as possible, and on the other, an incredibly complex thing. It would seem that this is just a service that allows you to write and read bytes. But there are thousands of different settings that control how these bytes are transmitted and how they are stored.
For example, there are settings that say how long messages should be stored in a topic. Indeed, unlike typical message brokers, which only transmit data, kafka also knows how to store it. In general, in its essence, Kafka is a commit log (a structure where you can append only to the end). This means that after the message has been received by Kafka, she will store it for as long as needed.
This “how much” is determined by the retention settings, and there are different options. You can specify that messages are deleted after some time, or when their total volume reaches a certain amount.
The removal itself does not happen immediately, but when Kafka decides. And due to different technical features, even a solution may not be enough. Why?
Kafka stores data in files on disk, these files are called segments, there is always one active segment where data is written, when this segment grows to a certain size or age, it becomes inactive, and a new active segment appears instead. So – the data is deleted only in inactive segments. Therefore, it may well be a situation when they put retention on one day (for example), but they do not change anything in the segment settings (and there, by default, the segment should live for a week or grow to a gigabyte) and then they wonder why the old data does not disappear.
There were unpleasant situations when we configured retention in topics, let’s say two weeks, and then, in case of abnormal situations, read the topics first and with horror found old data there, which was re-processed.
The general rule of thumb is to never base your logic on trusting Kafka’s data cleansing engine. She simply does not give such guarantees.
Compaction
And besides simple deletion, there is also the so-called compaction. This is when Kafka deletes not just old messages, but all previous messages with the same key (about the keys will be further). Here, in fact, we are deleting messages inside the topic. Why is this needed?
Compression allows us to save space for storing data that we don’t need. If we record the changes of an entity, and we do it in the form of snapshots (the current state of the entity after the change), then we no longer need the previous versions, the latest snapshot is enough. Compression is just about removing these previous versions.
Compressed topics can be thought of as tables in a relational database, where there will always be one value for one key. Cool? Developers read the documentation up to about this point, then write services where no more than one message per key is expected, and then … they cry.
The real deletion of data occurs again in inactive segments and under certain circumstances. There are a number of configuration parameters that control all this, but the bottom line is that the data won’t disappear for a long time, and this should be taken into account in your designs.
Tombstones
And finally, another interesting thing about the compact. Publishing a message with an existing key to a compressed topic is essentially an UPDATE operation. And if we can change, then we must be able to delete. To delete, you need to send a message with a key and an empty body (literally pass NULL instead of a body). And such a combination is called a tombstone – a kind of null terminator of the history of one entry. Let’s call this combination the deletion mark.
So, these labels are stored in the topic so that consumers (consumers are services that read from Kafka), when they reach them, understand that a record with such and such a key is already done, and this fact needs to be processed. But besides this, they themselves are also deleted after some time, without leaving any traces of the original record inside the topic. The deletion time is configurable separately. And this time should not be made too short, especially if you do not know all the consumers of your topic. After all, if the mark is removed before some leisurely consumer reads it, then for him the record will not be deleted at all, but will remain forever.
It all seemed to be well thought out and clearly described, in general, nothing foreshadowed trouble. We came up with a service that reads a list of current events from a topic and stores it all in memory. There are many sporting events, but they all end sooner or later, and then you can delete them. We did the deletion through the same marks in the topic with the configured compaction.
But after some time, we noticed that the start time for new instances of our service takes more and more time. Long story short, it turned out that labels are not removed, despite all the correct configuration parameters.
There is even KIP-534 , which should already be fixed, but we have not updated our kafka yet, so for now we are living with this bug. The solution was to add another delete policy so that records are deleted after a certain time, and in order not to lose events from the distant future, for which there are no changes, we made periodic fake updates.
Offsets And Commits
I already wrote above that Kafka is not really a message broker. Yes, there producers publish messages, and consumers subscribe to them and then read, and even commit something, but there are important differences that drive newcomers into confusion. I often hear the questions “how to re-read a message”, “how to delete it after reading it”, “how can the concierge notify the producer about successful processing” or “why do I receive the next message if I have not committed the previous one”. All this is due to the fact that the experience of working with standard brokers is not very good for kafka. The point is that these are not the commits that the developers are used to.
To understand this issue, it is easier to imagine a kafka topic as a stream (stream, not a thread). File or buffer in memory. And working with such a stream consists in the fact that we connect to it, indicate the position from which we want to read the data, and then in the loop we read everything in order. And we do not need to tell Kafka in any way that we have successfully read something. If the consumer returned something during the current call, the next message will be returned to us during the next call.
The starting position that we specify when connecting is called the offset. It can be set as an absolute value (100500), and a relative value (from the beginning or from the end). Since most scenarios imply that after restarting the service, it needs to read from the same position where it stopped last time (and for this you need to transmit the last read offset when connecting), Kafka provides a mechanism out of the box for simplification.
The concept of consumer groups is introduced, and (in a nutshell) they are able to store their active offsets. In general, the main purpose of consumer groups is horizontal scaling, but we will leave this for later.
And when a new consumer is added to the group, he begins to read messages from the offset, which will be next to the saved one. And a commit in the context of Kafka is not a confirmation that the message has been successfully read and processed, but simply storing the current offset for a given consumer group. Once again, there is nothing to do with confirmation.
Exactly Once Consumers
Against the background of such news, it turns out that the frequency of commits may not coincide with the frequency of receiving messages. If we have a high density of messages, sending commits to each one can significantly boost performance, and for high-load systems, offsets are committed less often. For example, every few seconds.
This approach can lead to the fact that some messages can be processed more than once. For example, the service restarted after processing message # 10, and only managed to commit # 5. As a result, after restarting it will re-read messages 6-10.
This feature should always be kept in mind and added to services to ensure idempotency (a complex word that means that repeated execution of an operation should not change anything). Some developers try to achieve exactly once semantics (when a message can only be read once) by flirting with the frequency of commits and different kafka settings. For example, explicitly submitting a commit for every post.
However, this approach not only significantly reduces performance, but also still does not guarantee exactly once. The message can be processed, but if the service or infrastructure crashes while the commit is being sent, this will cause the same message to be read again after the service is restarted.
Therefore, when designing your services, it is always best to assume that reading from kafka has at least once semantics (it will be read one or more times). It is worth noting here that for higher-level APIs (Kafka Streams, ksqlDB), exactly once processing is possible out of the box, and it will also appear in future versions (which may already be) of the Producer / Consumer API clients.
Consumer Groups for Assign
Somehow we noticed an invasion of strange consumer groups in the cluster. Usually consumer groups are deliberately called, the name of the service, product or team is indicated there, and then by this name you can find the consumers of the topic. And these strange groups were empty (did not store any offsets), and were called without any special frills – just goofy GUIDs. Where did they come from?
In general, the consumer of the group is an excellent mechanism for light-hearted scaling of reading, when Kafka hides from the developers the complexity of redistributing parts between consumers in case of adding or removing from the group. But for those who like to keep everything under control, the possibility of manual control is provided.
When a consumer connects using the Assign () method , rather than Subscribe (), he gets full control over the situation and can specify which partisans he wants to read from. In this case, the group consumer is not needed, but for some reason, it still needs to be specified when creating a consumer, and it will be created in the cluster.
And our losses turned out to be consumer groups, created by a service that used Assign (). But why are there a lot of them and where does the GUID come from?
It turned out that the example .NET client from the official repository used a GUID to name the group . In the vast majority of GUID scenarios, we need a unique identifier. And in this case, we used code that generates a new GUID (Guid.NewGuid () in .NET). As a result, at each start of the service, a new consumer group was created, and the old one did not disappear. It all looked as strange as possible, completely unlike the intention of the creators.
During another study of consumer examples with Assign (), we suddenly realized that the constructor new Guid () is used there. And the result of its work will not be a unique GUID, but a default value consisting of all zeros. It turns out that in this example, a constant was used as the group name, which did not change when the services were restarted. Moreover, you can use this constant for all consumers in general, and not be limited to one service.
So use constants for consumer groups in all scenarios – both Subscribe () and Assign ().
Client Libraries
If you start your acquaintance with Kafka with a book (and this is one of the best ways), then most likely the work of clients there will be described using Java as an example.
There will be a lot of interesting and correct things written, for example, the fact that the consumer’s code of the consumer hides a rather complex protocol under the hood. In which, in addition to the data reading itself, there are many details of working with consumer groups, balancing and so on.
This is probably why there are so few client libraries. There are essentially two of them – out of the box, running under the JVM and librdkafka, written in C, and used under the hood of the libraries of all other languages. And in their work there is one significant difference associated with the publication of offsets. Java clients do everything in one thread, and all communication happens during the call to the poll () method. This method essentially reads messages from Kafka, but it also does other work – publishing offsets, transactions, etc. Everything happens in one thread and the developer can be sure that if he read the message, then commits some kind of offset, and the service crashes before calling the poll method, then this offset will not be saved in the kafka, and when the service is restarted, this message will be read again …
But librdkafka works differently. There is a background thread that periodically sends commits. So after calling the Commit method, the commit may or may not reach Kafka. To make matters worse, with default settings, the commit may be written, but the message may not be processed (there are more details here). Therefore, in librdkafka, in most scenarios, it is better to do these settings.
Default partitioners
Our main stack was .NET, but somehow we decided to dilute the boring life by adding a little (as it seemed to us) JVM to it – namely Scala. What for? Well, because Kafka itself is written in javoskale and it is on the JVM that a higher-level API is available – Kafka Streams. The difference in these APIs is the same as between C and python for reading files. In the first case, you will have opening (and closing) a file, allocating (and freeing) a buffer, loops and all the other delights of a low-level bytetresh. Well, in the second – a simple one-liner.
In kafka streams, topics are provided in the form of, hmm, streams, from which you can read and, for example, join with other streams (topics) by key. Or write a predicate and filter the message by criterion.
So we wrote some code, ran it, but it doesn’t work. She doesn’t swear, but she doesn’t do anything either. They began to dig and dug up interesting things.
To fully understand and appreciate the interestingness, let’s delve a little deeper into such concepts of kafka as keys and partitions. Messages in kafka are stored in topics, and topics are broken down into partitions. Each partisan is a kind of shard. Data from one topic can be divided into different parts, which can be on different brokers and, accordingly, serve more producers and consumers.
Newbies often confuse partishens (shards) with replicas (copies). The difference is that the partition stores part of the topic data, and the replica stores all the topic data. These two things are not mutually exclusive, and in most cases topics have several partisans and several replicas. Partitions are used to improve performance, while replicas are used to improve reliability and availability. The increase in productivity is achieved due to horizontal scaling of consumers, and when using the recommended approach with a consumer, groups of one party can only read one consumer at a time. Therefore, the scaling limit is the number of partitions.
The logic of partitioning is that data, according to certain criteria, fall into one or another partition. You can, of course, write to everything in turn, like a normal load balancer, but this approach does not work well for many typical scenarios in which it is necessary that messages related to one entity (for example, order changes) are always processed by the same topic the same copy of the consumer. Therefore, different hash functions are used to determine the partition where it should be written by the key value.
This all starts to get complicated, and here again thanks to the Kafka developers because they made it simpler. Yes, when recording a message, you need to specify a partition, but an automatic selection mechanism has been added to the clients.
This choice is made using the so-called partitioner. In fact, this is the implementation of some kind of hashing function. And there is even a default partitioner that just works.
But back to our problem. It turned out that Scala and .NET clients have different default partners. In our case, there were two services based on different technologies, which were written in one topic. And because of this difference, messages with the same keys ended up in different partitions.
There are two conclusions. You need to check the default partisans if you have several services writing in one topic. Better yet, design systems so that only one service writes to each topic.
Timestamps
Every message in Kafka has a timestamp field. And it would be logical to expect that it is filled by the broker at the moment the message is added. But … not a fact.
There is an opportunity, firstly, to set this time explicitly, but there are also two options for what to do if the time is not set. You can use the time on the producer’s side when he sent the message, or the time on the broker’s side when this message was added to the topic.
Therefore, caution should be exercised when relying on timestamp messages in kafka, especially if the topic producer is not under your control. In this case, it is better to transfer the messages to your topic, and there you can already set the time as you like.
Zookeeper vs Kafka
Kafka is a fairly old mature product (since 2011). During its development, some APIs have changed, and some have been replaced by others.
For example, to connect, we first used the Zookeeper address (which is a necessary component of Kafka up to version 2.8.0), and then we began to set the addresses of the kafka brokers themselves (the very bootstrap servers that we wrote about above). Now it is recommended to use bootstrap servers, but connection via zookeeper also works and is used in some utilities.
We had an interesting problem when the consumer group was removed, but metrics continued to be published on it. It turned out that the group was deleted using a utility that connected to the zukiper, and the metrics were collected by the exporter, which was connected via bootstrap servers. And the group didn’t really succeed at all.
Conclusion – do not use outdated protocols, or at least do not interfere with new ones.
Conclusion
Here’s a selection of facts and misconceptions about Kafka. We really hope that the article will help you get around the rake that we were stepping on.


About The Author: Yotec Team
More posts by Yotec Team